Poster

Click the poster to view the PDF version
How effectively can discriminative model improve motion generation quality without any additional inference cost?
TL;DR: We propose SoPo, a semi-online preference optimization method, combining the strengths of online and offline direct preference optimization to overcome their individual shortcomings, delivering enhanced motion generation quality and preference alignment.
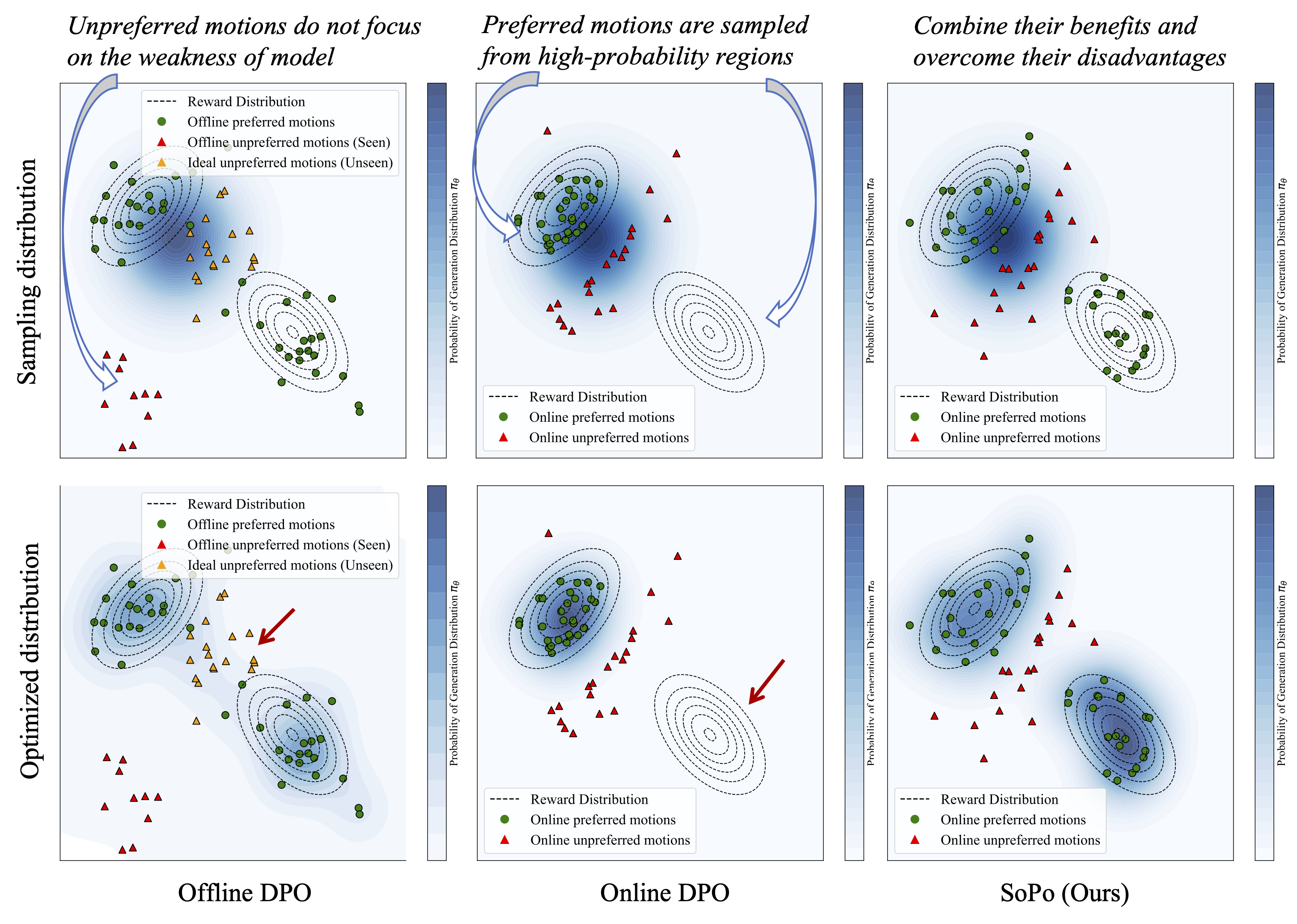
Text-to-motion generation is essential for advancing the creative industry but often presents challenges in producing consistent, realistic motions. To address this, we focus on fine-tuning text-to-motion models to consistently favor high-quality, human-preferred motions—a critical yet largely unexplored problem. In this work, we theoretically investigate the DPO under both online and offline settings, and reveal their respective limitation: overfitting in offline DPO, and biased sampling in online DPO. Building on our theoretical insights, we introduce Semi-online Preference Optimization (SoPo), a DPO-based method for training text-to-motion models using "semi-online" data pair, consisting of unpreferred motion from online distribution and preferred motion in offline datasets. This method leverages both online and offline DPO, allowing each to compensate for the other’s limitations. Extensive experiments demonstrate that SoPo outperforms other preference alignment methods, with an MM-Dist of 3.25% (vs e.g. 0.76% of MoDiPO) on the MLD model, 2.91% (vs e.g. 0.66% of MoDiPO) on MDM model, respectively. Additionally, the MLD model fine-tuned by our SoPo surpasses the SoTA model in terms of R-precision and MM Dist. Visualization results also show the efficacy of our SoPo in preference alignment.